累積カイ二乗検定(るいせきかいじじょうけんてい、累積カイ二乗法、英:Cumulative chi-squared test)は統計学における仮説検定の一種である。東京大学の竹内啓、広津千尋らによって1966年に田口玄一が導入した累積法を修正して1979年に提案された統計学的仮説検定法である。2つの変数の間、2つの母集団の間に差がないという帰無仮説に対して、対立仮説として帰無仮説の棄却ではなく、一つの変数または両方の変数が増加または減少をする傾向性がある、といった対立仮説を設定する。例えば、薬剤の効果を調べる試験において複数の投与量ごとの反応の程度を見る、といった順序尺度で表される変数について、投与量の水準が増加するにつれて反応が変化する、という対立仮説を立てる。同様の目的のための検定法としてはウィルコクソンの符号順位検定などがある。
帰無仮説
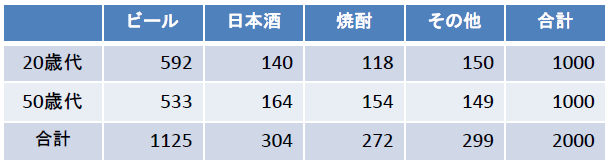
2つの母集団 A, B から抽出して得られる観測値 により母集団の優劣を比較する場合を考える。各観測値は順序のある 個の水準のどれかに分けられるものとしたとき、各観測値を で表し、 が水準 に入る確率を とする。この場合の帰無仮説は2つの母集団 A, B の間に差がないということを表すため次の式になる
対立仮説
単に帰無仮説を棄却するのであれば対立仮説は次のようになる
しかしこの対立仮説ではA, B の優劣を表すことができない。そこで各水準間に順序があることを考えて次の対立仮説を想定する。
- • • • • • •または
- • • • • • • •または
ただしは累積確率を表す。
対立仮説 は母集団 A が若い水準(優れているまたはその反対)に分類されることが多いことを表す。
対立仮説 はどの累積確率で比較しても同等以上であることを表す。
検定統計量
上記の帰無仮説 は次の が同時に成り立つことと同じである。
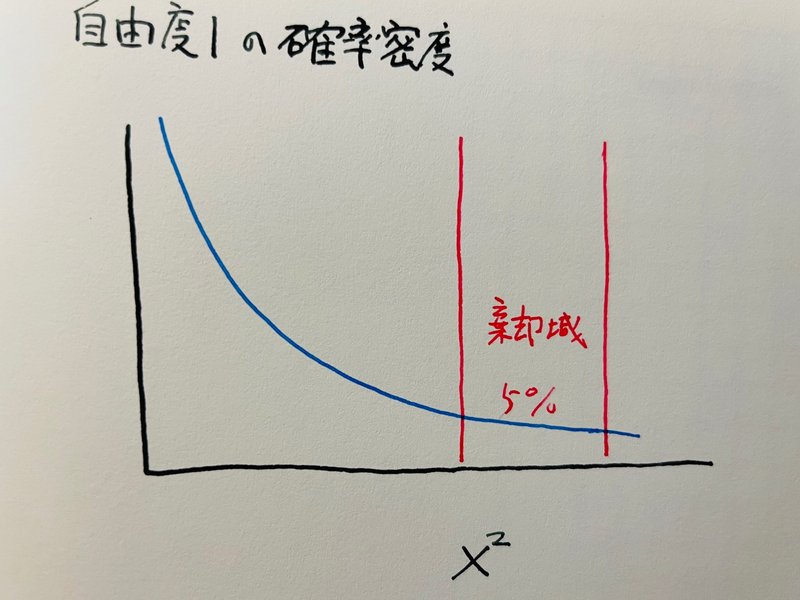
この についての自由度 1 のカイ二乗値
- *
この累積するカイ二乗値を結合して一つの検定統計量
とする。
適用
傾向のある対立仮説を想定する検定問題で
- いくつかの二項分布の比較
- 2つの多項分布の比較
- いくつかの多項分布の比較
- 2×k 分割表における独立性の検定
などに用いることができる。
用量反応関係の検定などにおいて累積カイ二乗検定の適用となる分割表のタイプには次のようなものが挙げられる
- m×2 分割表(順序あり)
- 2×l 分割表(順序あり)
- m×l 分割表(列に順序あり)
- m×l 分割表(行・列とも順序あり)
脚注
関連項目
- コクラン・アーミテージ傾向検定
- シャーリー・ウィリアムズ検定
- ウィルコクソンの符号順位検定
- クラスカル・ウォリス検定
- 実験計画法
- 推計統計学